【文章內容使用 Gemini 1.5 Pro 自動產生】
Dart DevTools:使用 CPU 分析器分析應用程式效能
無論您是使用 Dart 編寫命令列工具的後端開發人員,還是使用 Flutter 建立應用的 UX 工程師,程式效能對專案的成功至關重要。命令列工具應將延遲降到最低,而應用程式應具有回應性和靈活性,並且沒有掉幀。作為開發人員,我們盡最大努力編寫高效能的程式碼,但有時不清楚為什麼我們的程式碼沒有按照預期執行。
在程式碼庫中追蹤效能問題可能是一項艱巨的任務。有許多方法可以編寫 Flutter 程式碼,使其執行速度比預期慢。有些方法顯而易見,而另一些方法則陰險地微妙。例如,您可能在特定情況下使用了錯誤的 API 或資料結構。
本文將透過一個簡單的案例研究來分析一個緩慢的 Dart 命令列介面 (CLI) 應用程式的效能。您將學習:
- 一般 CPU 分析器及其重要性。
- 與 Dart 和 Flutter 捆綁在一起的取樣 CPU 分析器。
有了對 CPU 分析的理解,我們將除錯程式的效能。我們將使用 Dart DevTools CPU 分析器和 dart:developer 的 UserTag 功能來精確找出效率低下的程式碼。我們有很多內容要介紹,所以讓我們開始吧!
注意:Dart DevTools 也稱為 Flutter DevTools,但不要與 Chrome DevTools 混淆。
案例研究:在 Dart 中實作 grep
考慮以下簡單的 Dart CLI 應用程式:
1 | // 檔案名稱:grep.dart |
grep.dart 程式實作了常見 Unix 工具的版本。它允許使用者在檔案中搜尋符合指定樣式的字元串。例如,給定一個名為 names.txt 的檔案,其中包含:
1 | $ cat names.txt |
讓我們找出所有包含字元串 'Fran' 的行:
1 | $ dart grep.dart names.txt 'Fran' |
太棒了!我們應該從 grep 中得到這個輸出。也就是說,names.txt 是一個 小 檔案。讓我們嘗試在一個更大的文字文件中找出所有 'Hummingbird' 的實例。如果我們在一個包含 437,000 行、147 MiB 的關於蜂鳥的文字檔上執行相同的程式會怎麼樣?
1 | $ dart grep.dart hummingbird_encyclopedia.txt 'Hummingbird' |
嗯……即使在 兩分钟 後,它也沒有完成。Unix grep 的效能如何?
1 | $ grep -n 'Hummingbird' hummingbird_encyclopedia.txt |
Unix 的 grep 搜尋了整個檔案,並在約 45 秒內返回了所有包含蜂鳥的行。顯然,我們的程式碼中有一些奇怪的地方需要調查。但是,我們如何識別效能問題的原因?與 Dart DevTools 捆綁在一起的 CPU 分析器 是一個很好的開始!
什麼是 CPU 分析器?
CPU 分析工具會追蹤程式在執行時花費時間的地方。為了提供最有效率的 CPU 分析體驗,Dart 虛擬機器 (VM)(為 Dart CLI 和 Flutter 應用程式提供動力)使用 取樣 CPU 分析器。當與 Dart DevTools 等工具一起使用時,您可以識別 Dart 程式中的效能瓶頸。
取樣 CPU 分析器採用統計方法來收集應用程式效能資料。它透過定期中斷執行緒並擷取當前呼叫堆疊和其他相關執行狀態的快照來收集樣本。這些樣本可以被處理,以便找出大約有多少時間花費在執行特定函數上,以及函數在不同呼叫堆疊上出現的頻率。
收集樣本的頻率稱為 取樣速率,以每秒樣本數(也稱為赫茲或 Hz)衡量。大多數取樣分析器具有 1000 Hz 或更高的取樣速率。更高的取樣速率會產生更詳細的 CPU 分析,但代價是在目標流程中更高的取樣負擔。在合理的取樣速率下,取樣 CPU 分析器非常有效,並且對被分析應用程式的效能特徵沒有影響。額外的優勢是,與追蹤分析器相比,收集的資料通常在分析方面計算成本更低。
深入探討:取樣分析器是如何運作的?
這部分將詳細介紹 Dart VM 的取樣 CPU 分析器的工作原理。在分析 CPU 分析時,您不需要了解這些細節。如果您不關心取樣 CPU 分析器的詳細資訊,請跳過此部分。
Dart VM 的取樣 CPU 分析器具有三個重要的元件:執行緒中斷器、樣本收集器和樣本處理器。
執行緒中斷器
執行緒中斷器 在一個專用的執行緒上運行,並在 VM 管理的每個執行緒上觸發表 CPU 樣本收集。執行緒中斷器通常處於非活動狀態,只在每個取樣間隔後喚醒一次。在每個取樣間隔之後,中斷器會遍歷執行緒列表,通知每個執行緒暫停並收集樣本。執行緒中斷器在不同平台上的行為略有不同,因為作業系統有特定的細節。
在大多數支援 基於訊號的控制流(Android 和 Linux)的平台上,SIGPROF 訊號會發送到每個執行緒。這會觸發一個 中斷,該中斷會呼叫 CPU 分析器在目標執行緒上註冊的訊號處理器,然後在繼續工作之前收集 CPU 樣本。
在其他不支持訊號(Windows 和 Fuchsia)或在某些情況下使用 SIGPROF 時效能不佳(MacOS 和 iOS)的平台上,執行緒中斷器使用系統呼叫在收集 CPU 樣本後顯式地暫停和恢復每個執行緒。在這種情況下,樣本收集是在執行緒中斷器執行緒上進行,而不是在被取樣的執行緒上進行。
樣本收集
一旦執行緒被中斷,CPU 分析器就會 收集樣本 以擷取執行緒的當前執行狀態。每個 樣本 包含以下類型的中繼資料:
- 執行緒和隔離區識別碼
- 執行緒的活動 使用者標記
- 收集時間戳
- 被取樣執行緒的當前堆疊追蹤
收集的堆疊追蹤由程式計數器 (PC) 列表組成,這些程式計數器對應於堆疊上找到的每個 Dart 和原生函數的返回地址。這些 PC 是透過一個稱為「遍歷堆疊」的過程收集的。在執行 堆疊遍歷 時,堆疊遍歷器使用頂部框架的框架指標 (FP) 和已知的每個堆疊框架佈局來查找並記錄與函數關聯的 PC 以及前一個堆疊框架的 FP。堆疊遍歷器會重複此過程,使用前一個框架的 FP 作為起點,直到它到達堆疊的末尾,如圖 1 所示。
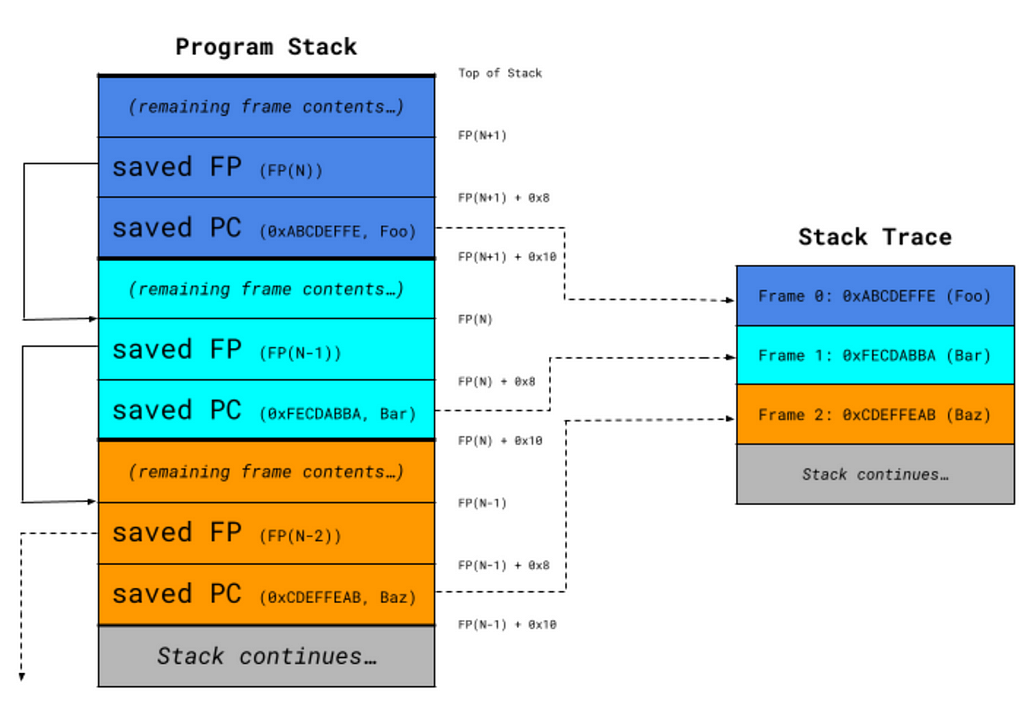
每個收集的樣本都儲存在 VM 的樣本緩衝區中,這是一個 循環緩衝區,可以儲存有限數量的 CPU 樣本。這允許 VM 避免在運行時進行額外的配置,這可能會對效能產生負面影響,或者 如果在訊號處理器中執行,可能會導致不好的事情發生。
樣本緩衝區的大小在運行時是固定的,一旦填滿,舊樣本將被分析器覆蓋為新樣本。樣本緩衝區填滿的速度取決於取樣速率和每個樣本的平均堆疊深度。例如,更高的取樣速率和更深的堆疊會導致緩衝區更快地繞回。在 DevTools 中,開發人員可以透過 選擇 低(1000 Hz)、中(4000 Hz)和高(20,000 Hz)取樣速率來控制樣本緩衝區繞回的速度。
樣本處理
當客戶端透過 VM 服務協定 請求 CPU 樣本分析時,CPU 分析器需要在將樣本發送給客戶端之前處理收集的樣本。分析器:
- 遍歷樣本緩衝區,使用篩選器只擷取客戶端指定的隔離區和時間範圍內的樣本。
- 符號化,或將 PC 對映到函數名稱,樣本集中每個堆疊框架。
- 將整個處理後的樣本緩衝區序列化為 JSON。
- 將 JSON 傳回給客戶端。
即使在分析器完成處理之後,CPU 樣本回應 仍然是低階的,需要開發人員工具進行額外的處理才能變得有用。例如,Dart DevTools 可以將 CPU 樣本列表轉換為各種結構表示,這些表示允許識別昂貴的函數(自下而上)、昂貴的呼叫路徑(呼叫樹 和 CPU 火焰圖),以及檢查個別方法的呼叫者和被呼叫者統計資料(方法表)。
使用 Dart DevTools 分析 Dart 和 Flutter 應用程式
現在您已經熟悉了取樣 CPU 分析器是什麼以及它們的工作原理,讓我們除錯 grep 實作的效能。讓我們使用 --observe 再次運行程式碼,並打開 Dart DevTools CPU 分析器標籤:
注意:在 DevTools 中測試 Flutter 應用時,您不需要使用 --observe 旗標。
1 | $ dart --observe grep.dart hummingbird_encyclopedia.txt 'Hummingbird' |
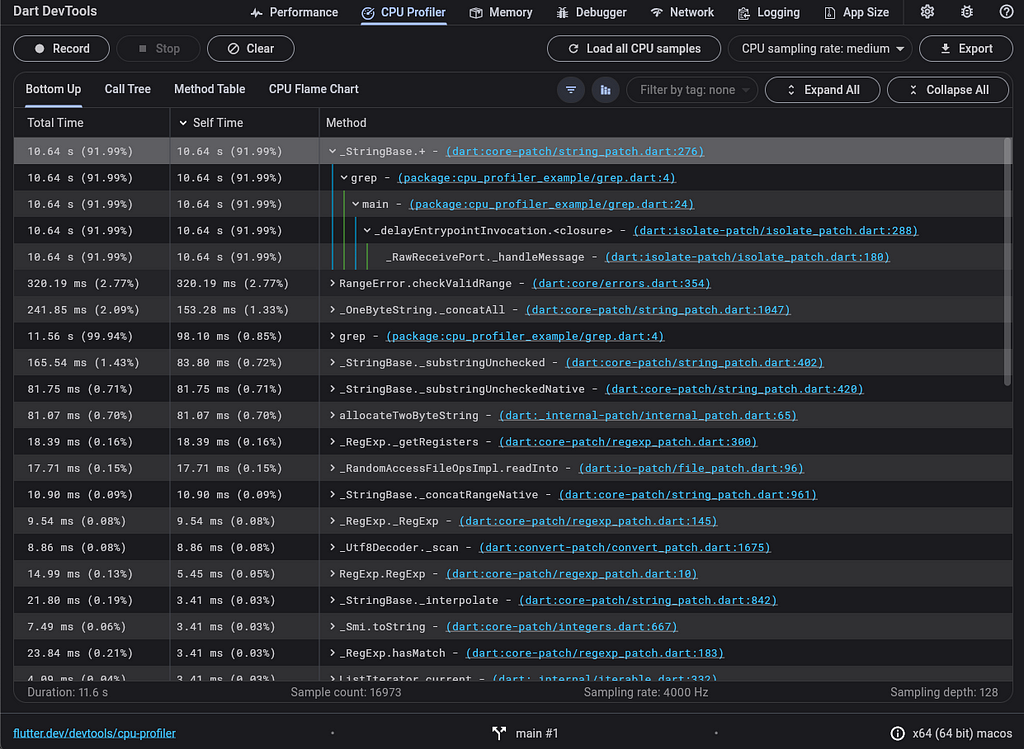
哎呀!在 11.6 秒的期間內收集的所有樣本中,隔離區將 90% 以上的 CPU 時間花費在執行 _StringBase.+ 上。這很可能與我們的效能問題有關,但可能不清楚 grep 函數中的哪個程式碼塊是導致延遲的原因。幸運的是,我們可以使用 使用者標記 进一步缩小对 _StringBase.+ 的昂贵呼叫的位置。
使用使用者標記對 CPU 樣本進行分類
當 Dart CPU 分析器中斷執行緒以收集新的樣本時,它會記錄隔離區當前設定的使用者標記。dart:developer 函式庫提供了 UserTag 類別,允許您指定和設定您感興趣的分析程式碼部分的自訂標記。
為了更好地了解我們在 grep 實作中花費時間的地方,我們可以使用使用者標記來 instrumentation 此函數:
1 | // 檔案名稱:grep.dart |
現在,讓我們重新運行程式碼並打開 CPU 分析器。若要查看已分類的分析,請從下拉選單中選擇 分組依據:使用者標記 選項:
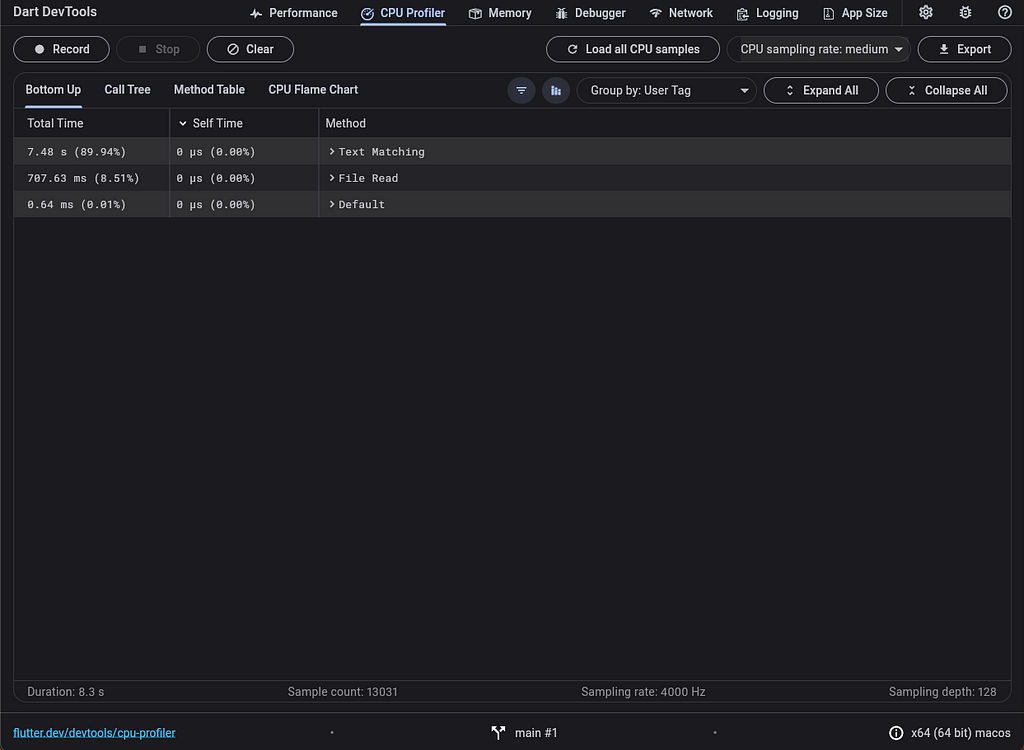
當我們展開 文字配對 標記時,我們確認 _StringBase.+ 方法在我們的文字配對迴圈中被呼叫:

有了這些資訊,我們應該能夠仔細查看我們的程式碼並找出問題所在:
1 | // 將 ‘文字配對’ 標記設定為目前的使用者標記。 |
找到了!我們犯了經典錯誤,多次將內容附加到 String,而不是使用 StringBuffer。將內容附加到 String 會建立一個新的字元串來儲存 _StringBase.+ 方法的結果。因此,每次我們找到匹配項時,我們都會將 output + foundMessage 複製到一個新的字元串中。
隨著 output 變長,將資料附加到它會變得更昂貴,需要 O(m*n) 來執行複製,其中 m 是匹配項的平均字元數,n 是最終字元串中的總字元數。如果我們使用 StringBuffer,我們不會在每次附加時複製 output,而是在函數結束時以單一的 O(n) 操作將匹配連接起來。
現在我們的應用程式使用 StringBuffer.writeln 而不是將內容附加到 String,讓我們看看我們的函數:
1 | // 檔案名稱:grep.dart |
讓我們再次運行測試,看看是否有任何改善:
1 | $ dart grep.dart hummingbird_encyclopedia.txt 'Hummingbird' |
使用 StringBuffer,我們可以在約 45 秒 內找出所有 'Hummingbird' 的實例。這好多了,幾乎與 Unix grep 實作相同!讓我們再看一下 CPU 分析器,看看是否可以進一步提高效能:
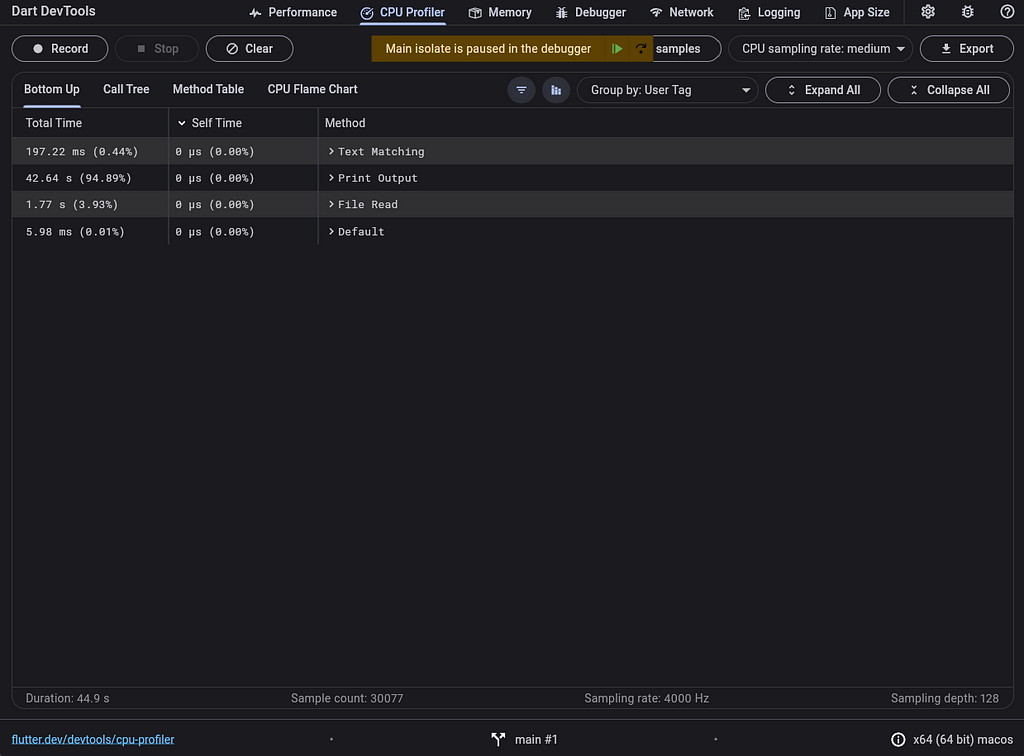
快速瀏覽分析告訴我們,我們大部分時間都花費在列印匹配項上,而實際的匹配只花費了約 200 毫秒。我們應該關注 '列印輸出' 標記下的程式碼:
1 | // 將 ‘列印輸出’ 標記設定為目前的使用者標記。 |
似乎我們沒有什麼可以做的,因為我們只對核心 dart:io 函式庫的成員 stdout.writeln 進行了一次呼叫。查看 分析器中的 CPU 火焰圖,我們看到這段程式碼在 SDK 中,我們無法在程式碼中獲得更多效能增益。
就這樣!
結語
從這篇文章開始,我們已經取得了很大的進展。我們:
- 使用 Dart 編寫了一個簡單的 grep 工具。
- 確定我們的程式效能很差。
- 了解了 CPU 分析器,並探索了 Dart VM 的取樣 CPU 分析器。
- 使用 Dart DevTools 的 CPU 分析器 找出並修復了程式的效能問題。
深入了解效能工具是一項重要的技能,正如我們在本文中所展示的,它可以幫助您找出程式碼中可能存在著微妙的效能問題。CPU 分析器只是 Dart DevTools 附帶的許多工具之一,可以幫助您更好地了解 Dart CLI 和 Flutter 應用的行為和效能。
在未來的文章中,我們將探索使用 Dart DevTools 除錯和優化應用的其他方法,包括:
在那之前,祝您編程愉快!
如果您願意,在 GitHub 上關注我 以了解我對 Flutter 和 Dart 虛擬機器的最新工作,以及我的其他個人專案。
Dart DevTools:使用 CPU 分析器分析應用程式效能 最初發佈在 Dart 上的 Medium,人們在那裡透過突出顯示和回應這個故事來繼續討論。
undefined