【文章內容使用 Gemini 1.5 Pro 自動翻譯產生】
基於 LLVM 的 Dart 編譯實驗
這篇文章講述了一個使用 LLVM 編譯器框架編譯 Dart 語言的實驗。乍看之下,這似乎沒有什麼意義,因為:

Dart 已經擁有一個出色的 虛擬機器,它使用 即時編譯 (JIT) 來獲得優異的效能。由於 Dart 是動態型別的(更準確地說,它是 可選型別的),JIT 編譯器是一個很自然的選擇——它可以使用運行時可用的型別來執行靜態編譯器無法進行的優化。
Dart-on-LLVM 看起來像是一項徒勞無功的工作的另一個原因是,儘管名稱如此,LLVM 並不是一個虛擬機器,而且直到最近它才適用於帶有垃圾回收的語言。所謂適用,我們指的是:
- 移動、精確(無洩漏)的垃圾回收
- 高度優化
這是因為,一旦優化器修改了您的程式碼,您就再也無法找到堆疊上的可垃圾回收指標。一種常見的策略是將所有指標移動到特殊的記憶體區域,但这會降低現代編譯器中的許多優化策略,現代編譯器依賴於區域變數的暫存器分配來發揮其魔力。您可以擁有良好的垃圾回收或完全的效能,但不能兩者兼得。
然而,LLVM 領域正在颳起新的風。最近,LLVM 以實驗性的 Statepoint 功能的形式增加了一些垃圾回收支援。這已被各種勇敢的團隊使用,包括 LLV8 實驗背後的人員和 Azul,他們正在將其用於 JVM 的新型頂級編譯器。

構建一個基於 LLVM 的真正虛擬機器似乎已從「不可能的任務」變成了僅僅是「困難的任務」。同時,強模式 使 Dart 更具靜態型別,並且減少了動態性。此外,我們 Google 正在為 iOS 構建 Flutter,而 iOS 禁止 JIT 編譯。這兩個發展都使 Dart 更符合 LLVM 專案的目標和權衡。
為什麼選擇 LLVM?
LLVM 是一個現代的、維護良好的開源編譯器框架,它為我們提供了許多優化和平台,而且是「免費的」。例如,有一個完整的 內聯 pass,可以將任何函數內聯到任何其他函數中,並包含關於何時這樣做的 啟發式方法。
它看起來也是一個開放、友好的社群,歡迎各種貢獻。
實驗目標
- 上下文是在提前編譯場景中的強模式 Dart
- 評估使用 Statepoint 支援精確、移動垃圾回收的可行性
- 評估效能
方法
我們(Erik Corry 和 Dmitry Olshansky)的實驗基於已停止的「Dartino」運行時。這是一個針對小型設備進行了優化的實驗性 Dart 運行時。與使用 DartVM 作為基礎相比,它對我們有一些優勢:
- 已經有一個由 Martin Kustermann 構建的 Dartino 的實驗性 LLVM 後端。它沒有垃圾回收支援,因此在記憶體不足時會崩潰。
- Dartino 利用了 Dart2JS 的許多機制,因此它不需要完整的解析器、前端等。我們用作輸入的 Dartino 位元組碼已經降低了许多困難的 Dart 功能。例如,閉包是物件,可選參數已變成了不同版本的函數。
- 我們都已經熟悉 Dartino。
- Dartino 附帶了一個相對完整的運行時,並且能夠運行大型應用程式,例如託管 Dart2JS。它沒有很多 Unix IO 支援,而且執行緒模型也不同,因此它不是一個直接替代品。
Dartino 中的垃圾回收
現有的 Dartino LLVM 實驗是在一段時間之前從 Dartino 分叉出來的,當時的垃圾回收非常簡單(半空間 Cheney 收集器,沒有分代,長時間暫停,2 倍記憶體佔用開銷)。我們從 Dartino 主分支中挑選了一些變更,以獲得更傳統的帶有寫入屏障的 2 代垃圾回收。沒有讀取屏障,收集是停止所有執行緒的,沒有併發垃圾回收(雖然 LLVM Statepoints 似乎確實支援這些功能,而且它們幾乎肯定被 Azul 在其閉源虛擬機器中使用)。
我們沒有從較新的 Dartino 版本中挑選壓縮舊分代的支援。

架構
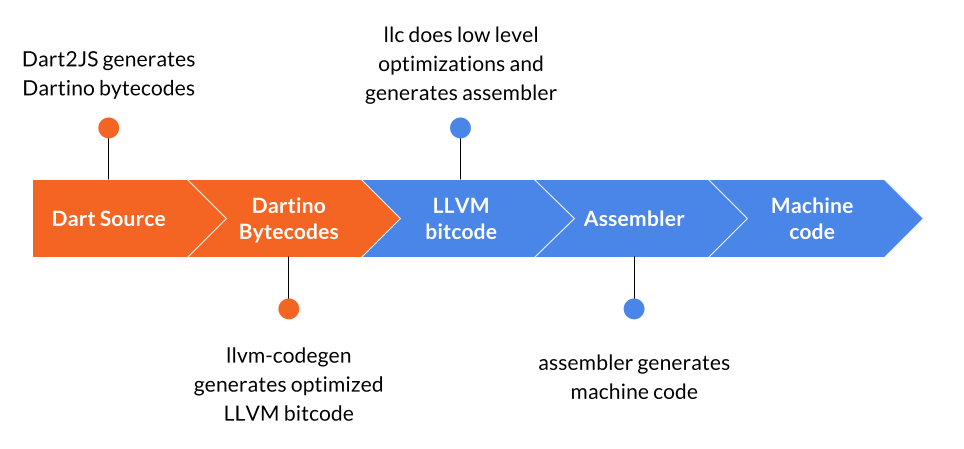
上面的流程顯示了從 Dart 原始碼到機器碼的路徑。在實際的實作中,第一部分將被基於「kernel」格式的內容替換(預先解析的 Dart 原始碼前端)。
翻譯成 LLVM 和高階優化
llvm-codegen 連結到我們自己的 LLVM 副本,並執行高階優化。在此階段,LLVM 維持指標在垃圾回收過程中有效的假設,但指標使用非預設的「地址空間」標記,這禁止 LLVM 以在存在移動垃圾回收的情況下不正確的方式推理其位元模式。各種自訂的 LLVM 內建函數用於標記可能發生垃圾回收的點。
由於標記指標,LLVM 位元組碼非常醜陋,有很多轉換和加法。因此,本文檔包含「LLVM 偽程式碼」,而不是真正的 .ll 檔案。如果您習慣於實際的 .ll 檔案,這看起來就像「寶貝的第一個 .ll 咿呀學語」,抱歉!以下程式碼表示 mem2reg 之後的動態分派,該 pass 將區域變數從堆疊提升到 SSA 暫存器中:
在優化器運行後,上面的相當費力的查找已從迴圈中移除,只剩下調用指令。這是可能的,因為類別指標在 Dart 中是不可變的,並且我們已將各種中繼資料附加到載入指令(未顯示),包括 invariant.load 和 never.faults(後者是我們 修補的 LLVM 版本 的新增功能)。
降低
一旦高階優化運行完成,我們將大多數內建函數降低為普通的 LLVM 指令。例如,寫入屏障簡化為一系列儲存(Dartino 使用卡片標記方案,這很大程度上歸功於 Urs 的 博士論文 第 6.2.3 節)。降低後,每個區域變數指標都在每個可能的垃圾回收點(基本上是每個調用)被一個不透明的內建函數重寫。這會抑制許多優化(這就是為什麼我們必須在降低之前進行優化 pass),但有兩個目的:
- 內建函數稍後將用於生成堆疊映射,詳細說明堆疊上可垃圾回收指標的位置。
- SSA 值被分解為垃圾回收前和垃圾回收後的值,這使得垃圾回收對優化器可見,並防止無效的程式碼生成。
調用現在看起來更像這樣(分派已從迴圈中提升出來,因此 %code 包含程式碼指標——迴圈未顯示)
轉換相當笨拙,在轉換後的調用中建立了一個特殊標記,並將其用作 gc.result 和 gc.relocate 調用中的參數。可垃圾回收指標仍然被特殊標記(使用非零地址空間,在上面的偽 LLVM 中未顯示),這在下一階段抑制了一些優化。
程式碼生成
最後一步是程式碼生成,由 LLVM 程式 llc 執行。這一步可以使用完全未修補的 ToT LLVM 透過命令 llc -O3 完成。目前唯一支援實驗性垃圾回收內建函數的後端是 x64,但我們沒有看到任何將 ARM 支援加入和上游化的根本性障礙。動態分派調用站點現在看起來像:
這使用 x64 的標準(主要是基於暫存器)調用約定。在每次調用之前,一堆暫存器會溢出到堆疊中,如果需要,垃圾回收可以在堆疊中移動它們。不支援被調用者儲存的可垃圾回收值(V8 和 DartVM 也不支援)。
效能
Dartino 位元組碼在一個非常動態的型別環境中針對簡潔性和緊湊性進行了優化。在此分析中,我們嘗試展望一個使用強模式並且在編譯時知道型別的場景。在這種情況下,方法的分派和對物件上成員變數的存取將更簡單、更快。為了更接近這種情況,我們在生成 LLVM 程式碼時使用了一些全程式分析。
最重要的結果是,如果只有少數類別具有方法 foo(),那麼我們會檢查這些類別並直接調用 foo() 方法。與某些類似虛擬函數表的分派機制不同,這讓 LLVM 可以在有意義的地方內聯方法。這是一個巨大的勝利,尤其是對於 getter 和 setter,這是 Dart 的一個很棒的功能。
編譯器仍然必須處理許多動態語言問題,它大多數都能正確處理(請參閱下面的測試狀態部分)。特別是,整數可能會溢出並隨時變成真正的堆分配數字物件。再加上運算子的重載,這使得即使是簡單的 for 迴圈也相當複雜。更多的靜態分析可能會改善這一點。
與真正的 DartVM 的一個區別是,我們不會檢查堆疊溢出,也不會在迴圈返回邊緣檢查執行緒中斷。根據 V8 的經驗,我們估計修復這個問題可能會損失大約 10% 的效能。
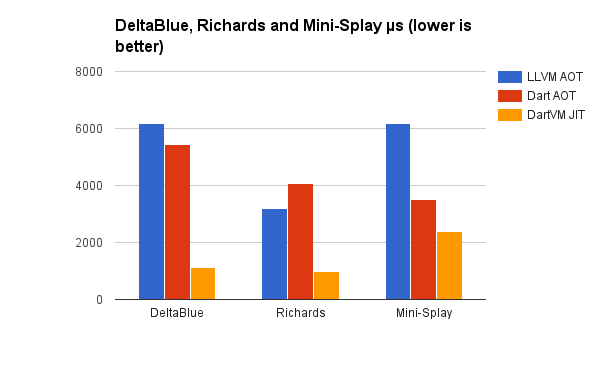
我們與常規的 JIT DartVM 以及已為 Flutter 加入到 DartVM 中的新的提前編譯支援進行了比較。基準測試 來自 Dartino。
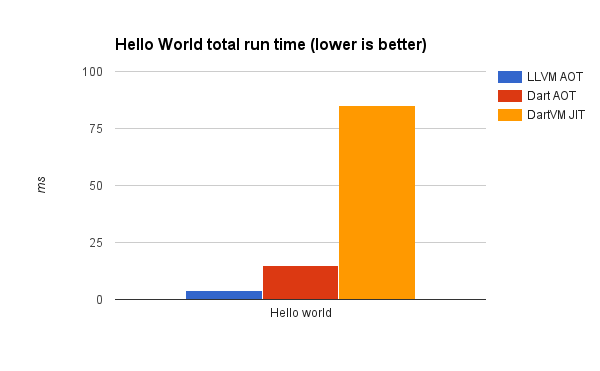
運行一個像 Hello World 這樣短暫的程式主要顯示啟動所需的時間。基於 JIT 的系統花費時間編譯程式碼,而這裡的兩個非 LLVM 解決方案都在啟動時反序列化資料堆。
效能結論
我們的效能與 Flutter 現有的提前編譯技術相當(這是一個移動的目標——這些測量是在 2016 年 11 月下旬在一台強大的 64 位 Linux 工作站上進行的)。JIT 仍然遙遙領先。我們正在運行的 Dartino 分支的垃圾回收效能還沒有達到標準。
我們還測量了啟動時間。Dartino-LLVM 為類別、常數和分派表生成靜態資料。這些資料由高度優化的 ld.linux 運行時連結器載入,它們的載入速度比目前的 Dart AOT 資料堆快照更快,從而為啟動提供了非常好的效能。對於啟動測試,CPU 調控器設定為「效能」。
關於相容性的說明
在這項研究中,我們並沒有特別關注獲得 100% 的 Dart 相容性。證明「困難的事情」是可能的,例如垃圾回收和異常處理,就足夠了。在某些情況下,我們採用了一種捷徑,表明真正的解決方案是可能的,而無需浪費時間實際實作真正的解決方案。以下是一些我們妥協的地方:
- 像 Dartino 一樣,我們沒有無限精度的整數。但是,我們確實會檢查所有整數運算是否溢出,並動態切換到裝箱數字表示形式(但是,裝箱表示形式只有 64 位,會換行)。
- 在 no-such-method(本質上是一個失敗的型別檢查)上,我們沒有遵循完整的 Dart 語義,這包括調用 no-such-method 方法並檢查是否存在與缺少的方法同名的 getter,並返回一個帶有「call」方法的物件。但是,我們確實會在安全點(可以進行分配的點)拋出異常。
- 我們不會在調用時檢查堆疊溢出,也不會在迴圈返回邊緣檢查中斷。LLVM 確實對此提供了實驗性支援。我們比較的解決方案確實支援這一點。V8 的經驗表明,修復這個問題可能會導致大約 10% 的效能下降。
- 我們的前端編譯器是一個修改過的 Dart2JS。由於 Dartino 已停止,它沒有跟上語言的最新變化,因此有一些測試我們無法運行。
- Dart 異常處理已完全實作,除了與 no-such-method 相關的異常。為此,我們使用了 LLVM 內建的異常處理支援,這看起來足以勝任這項任務,並且與 Dart 的異常模型非常吻合(這與 LLVM 設計的 C++ 並沒有太大的不同)。
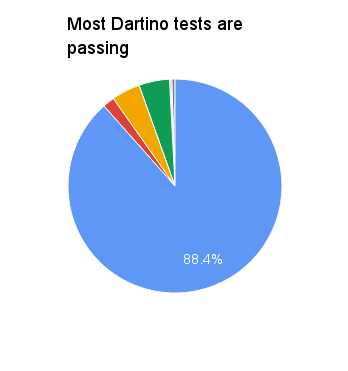
總之,我們通過了 Dartino 可以通過的近 90% 的測試。在我們失敗的測試中,最大的原因是編譯器前端的問題和處理 no-such-method 事件的問題。
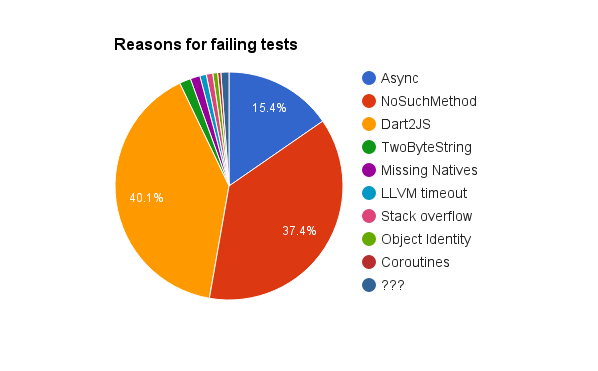
在大約 11.6% 的失敗測試中,以下是它們失敗原因的細分:
結論
實驗性的 LLVM 垃圾回收支援似乎在 x64 上完全正常工作。
原型的效能與我們更成熟的基於 DartVM 的提前編譯解決方案相當。
對於效能分析,我們沒有使用 Dart 強模式,預計這將產生發揮 LLVM 優勢的優化機會。但是,我們正在使用一些封閉世界假設,我們認為這是現實的。
我們能夠僅使用未修補的 LLVM ToT 版本將最後階段從 LLVM 位元組碼編譯為機器碼(在上面的流程圖中以藍色標記)。我們觀察到,在此階段執行的優化 (-O3) 並沒有導致任何錯誤編譯或垃圾回收問題。
未來
關於如何以及是否將這種方法用於 Dart 或 Flutter 尚未做出決定,但以下是一些關於可以探索的有趣方向的隨機想法。
- 擁有一種自定義的語言,而不是帶有控制程式碼的 C++,來編寫運行時例程。後端將是帶有 Statepoint 的 LLVM。(目前的版本中有一個小的 Forth 實驗,但需要更強大的東西才能編寫非常簡單的原生例程)。
- 包裝 64 位整數會產生什麼影響?
- 我們如何使用全程式知識來生成程式碼,同時仍然允許並行編譯大型專案?
參考
LLVM 垃圾回收支援 http://llvm.org/docs/Statepoints.html
Dartino-LLVM 儲存庫 https://github.com/dartino/sdk/tree/llvm
修改後的 LLVM 儲存庫 https://github.com/ErikCorryGoogle/llvm
Urs Hölzle 博士論文: http://hoelzle.org/publications/urs-thesis.pdf
LLV8: https://github.com/ispras/llv8
基於 LLVM 的 Dart 最初發佈在 dartlang 上的 Medium,人們在那裡透過突出顯示和回應這個故事來繼續討論。