【文章內容使用 Gemini 1.5 Pro 自動產生】
在 Flutter 中建立自訂渲染器並渲染 3D 場景。 Flutter 3.24 版本引進了一個新的低階圖形 API,稱為 Flutter GPU 。還有一個由 Flutter GPU 支援的 3D 渲染函式庫,稱為 Flutter Scene (套件:flutter_scene)。Flutter GPU 和 Flutter Scene 目前都處於預覽階段,僅在 Flutter 的 主頻道 上可用(由於依賴實驗性功能),需要 啟用 Impeller ,並且可能偶爾會引入重大變更。
本文包含這兩個套件的兩個「入門」指南:
🔺 進階: 使用 Flutter GPU 入門
💚 中級: 使用 Flutter Scene 進行 3D 渲染
使用 Flutter GPU 入門 ⚠️ 警告!⚠️ Flutter GPU 最終是一個低階 API。絕大多數將從 Flutter GPU 的存在中受益的 Flutter 開發人員很可能會透過使用在 pub.dev 上發佈的更高階渲染函式庫來做到這一點,例如 Flutter Scene 渲染套件。如果您對 Flutter GPU API 本身不感興趣,而只是對 3D 渲染感興趣,請跳到 使用 Flutter Scene 進行 3D 渲染 。
哦,真閃亮。這是一個射線行進的符號距離場。您可以使用 Flutter GPU 渲染它,但使用 [自訂片段著色器](https://docs.flutter.dev/ui/design/graphics/fragment-shaders) 也完全有可能。
使用 Flutter GPU 入門 Flutter GPU 是 Flutter 內建的低階圖形 API。它允許您透過撰寫 Dart 程式碼和 GLSL 著色器在 Flutter 中建立和整合自訂渲染器。不需要原生平台程式碼。
目前,Flutter GPU 處於早期預覽階段,並提供基本的柵格化 API,但隨著 API 逐漸穩定,將會繼續新增和改進更多功能。
Flutter GPU 還需要 啟用 Impeller 。這表示它只能在 Impeller 支援的平台上使用。在撰寫本文時,Impeller 支援:
iOS(預設啟用)
macOS(選擇性預覽)
Android(選擇性預覽)
我們對 Flutter GPU 的目標是最終支援所有 Flutter 的平台目標。最終目標是促進 Flutter 中跨平台渲染解決方案的生態系統,這些解決方案對於套件作者來說易於維護,對於使用者來說易於安裝。
3D 渲染只是一個可能的用例。Flutter GPU 也可以用於建立專用的 2D 渲染器,或者執行更非正統的操作,例如渲染 4D 空間的 3D 切片,或投影非歐幾里德空間。
由 Flutter GPU 支援的自訂 2D 渲染器的絕佳用例範例將是依賴骨骼網格變形的 2D 角色動畫格式。Spine 2D 就是一個很好的例子。這種骨骼網格解決方案通常具有動畫剪輯,這些剪輯會操縱層次結構中骨骼的平移、旋轉和縮放屬性,並且每個頂點都具有一些關聯的「骨骼權重」,這些權重決定哪些骨骼應該影響頂點,以及影響程度。
使用像 drawVertices 這樣的 Canvas 解決方案,需要在 CPU 上對每個頂點應用骨骼權重轉換。使用 Flutter GPU,骨骼轉換可以以統一陣列或甚至紋理取樣器的形式傳遞到頂點著色器,允許根據骨骼狀態和每個頂點的骨骼權重在 GPU 上並行計算每個頂點的最終位置。
說到此,讓我們透過一個溫和的介紹來開始使用 Flutter GPU:繪製您的第一個三角形!
將 Flutter GPU 加入您的專案 首先,請注意 Flutter GPU 目前處於早期預覽狀態,可能會發生 API 斷裂。目前 API 已經可以實現很多功能,但是有經驗的圖形工程師可能會注意到一些缺失的常見功能。Flutter GPU 在接下來的幾個月裡將會新增許多功能。
基於這些原因,強烈建議您在針對 Flutter GPU 開發套件時,暫時使用 主頻道 的頂端。如果您遇到任何意外行為、錯誤或有功能請求,請使用標準的 Flutter 問題範本 在 GitHub 上提交問題。與 Flutter GPU 相關的所有追蹤問題都標記為 flutter-gpu 標籤 。
因此,在試驗 Flutter GPU 之前,請透過執行以下命令將 Flutter 切換到 main channel。
1 2 flutter channel main flutter upgrade
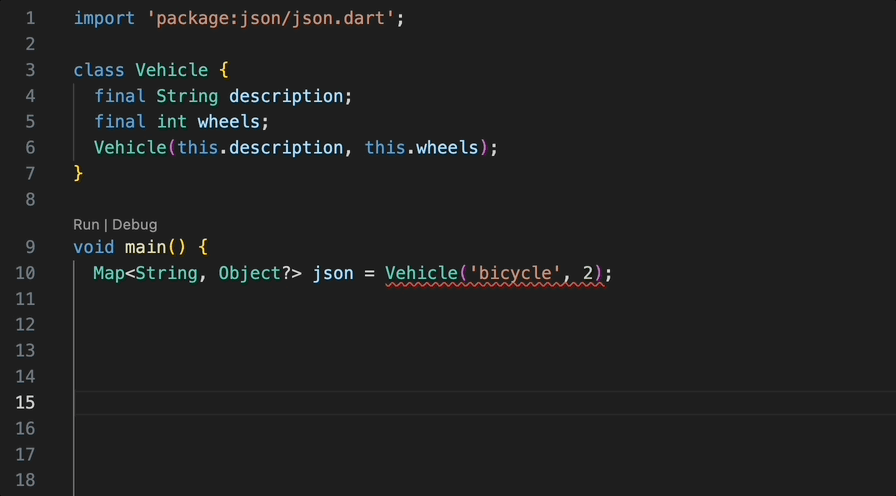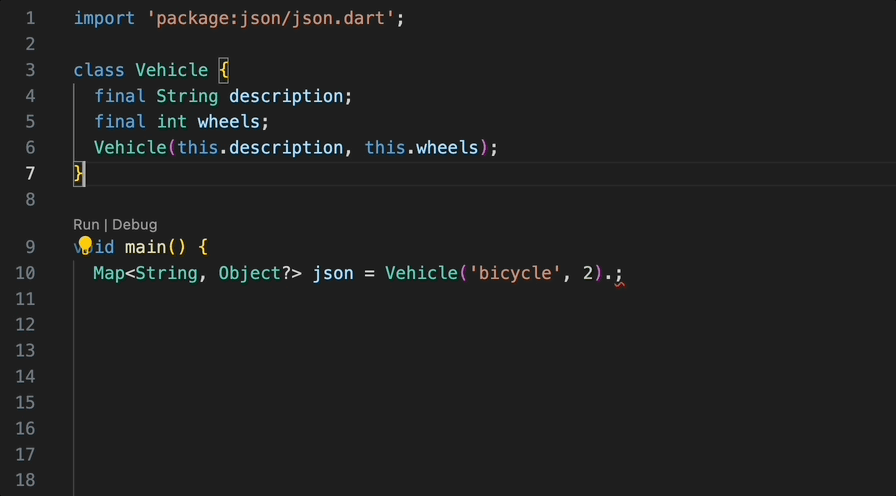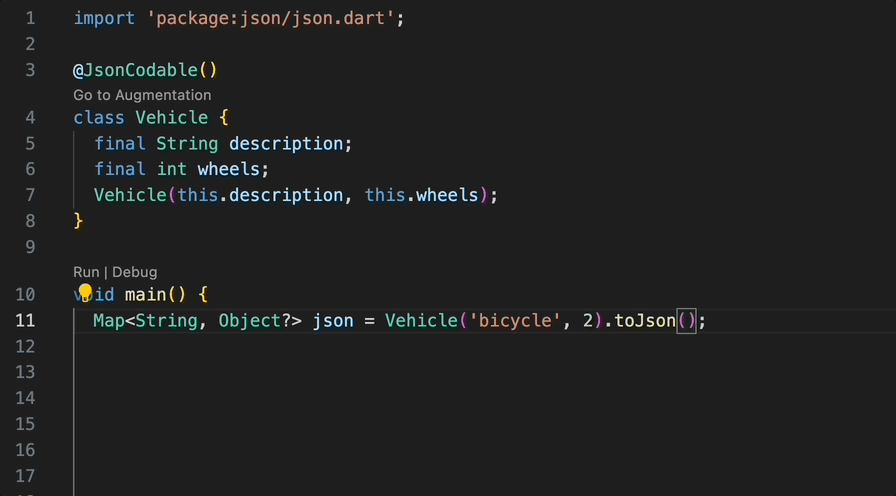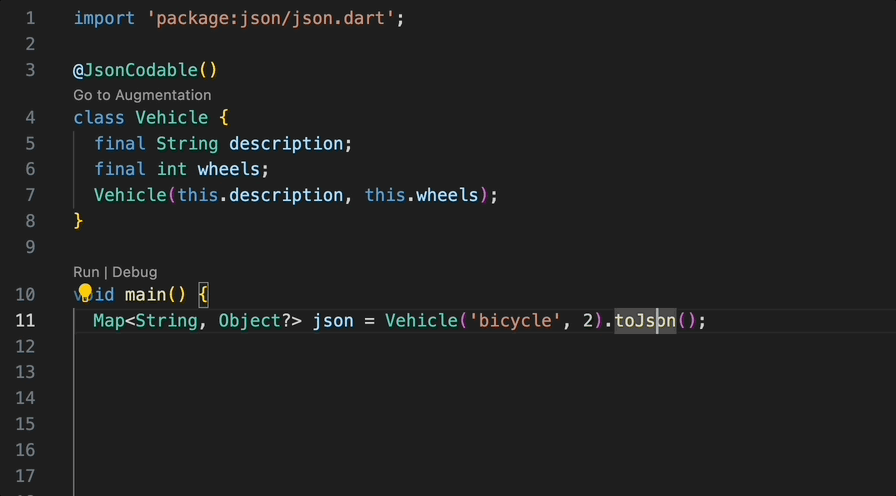
現在建立一個新的 Flutter 專案。
1 2 flutter create my_cool_renderer cd my_cool_renderer
接下來,將 flutter_gpu SDK 套件加入到您的 pubspec 中。
1 flutter pub add flutter_gpu --sdk=flutter
建立和匯入著色器捆綁包。 為了使用 Flutter GPU 渲染任何東西,您需要撰寫一些 GLSL 著色器。Flutter GPU 的著色器與 Flutter 的 片段著色器 功能所使用的著色器具有不同的語義,特別是在統一繫結方面。您還需要定義一個頂點著色器,與片段著色器一起使用。
從定義最簡單的著色器開始。您可以將著色器放置在專案中的任何位置,但是對於此範例,請建立一個 shaders 目錄,並使用兩個著色器填充它:simple.vert 和 simple.frag。
1 2 3 4 5 6 7 // 複製到:shaders/simple.vert in vec2 position; void main() { gl_Position = vec4(position, 0.0, 1.0); }
在繪製三角形時,您將擁有一個定義每個頂點的資料列表。在本例中,它僅列出 2D 位置。對於這些頂點中的每一個,簡單的頂點著色器都會將這些 2D 位置分配給剪輯空間輸出內在 gl_Position。
1 2 3 4 5 6 7 // 複製到:shaders/simple.frag out vec4 frag_color; void main() { frag_color = vec4(0, 1, 0, 1); }
片段著色器甚至更簡單;它輸出一個 RGBA 顏色,範圍為 (0, 0, 0, 0) 到 (1, 1, 1, 1)。因此,所有內容都將被著色為綠色。
好的,現在您有了著色器,請使用 Flutter 的提前編譯 (AOT) 著色器編譯器將它們編譯。為了為著色器捆綁包設定自動化的建置,我們建議您使用 flutter_gpu_shaders 套件。
使用 pub 將 flutter_gpu_shaders 作為專案中的常規相依性加入。
1 flutter pub add flutter_gpu_shaders
Flutter GPU 著色器捆綁到 .shaderbundle 檔案中,可以作為常規資產添加到專案的資產捆綁包中。著色器捆綁包包含針對平台目標的編譯著色器來源。
接下來,建立一個著色器捆綁包宣告檔案,描述著色器捆綁包的內容。將以下內容添加到專案根目錄中的 my_renderer.shaderbundle.json。
1 2 3 4 5 6 7 8 9 10 { "SimpleVertex": { "type": "vertex", "file": "shaders/simple.vert" }, "SimpleFragment": { "type": "fragment", "file": "shaders/simple.frag" } }
著色器捆綁包中的每個條目都可以具有任意名稱。在本例中,名稱是「SimpleVertex」和「SimpleFragment」。這些名稱用於在您的應用程式中查找著色器。
接下來,使用 flutter_gpu_shaders 套件建置 shaderbundle。您可以透過啟用實驗性的「原生資產」功能來新增一個掛鉤,該掛鉤會自動觸發建置。使用以下命令來啟用原生資產並安裝 native_assets_cli 套件。
1 2 flutter config --enable-native-assets flutter pub add native_assets_cli
啟用原生資產功能後,在掛鉤目錄下新增一個 build.dart 脚本,它將自動觸發建置著色器捆綁包。
1 2 3 4 5 6 7 8 9 10 11 12 13 // 複製到:hook/build.dart import 'package:native_assets_cli/native_assets_cli.dart'; import 'package:flutter_gpu_shaders/build.dart'; void main(List<String> args) async { await build(args, (config, output) async { await buildShaderBundleJson( buildConfig: config, buildOutput: output, manifestFileName: 'my_renderer.shaderbundle.json'); }); }
進行此更改後,當 Flutter 工具建置專案時,buildShaderBundleJson 將建置著色器捆綁包,並將結果輸出到套件根目錄下的 build/shaderbundles/my_renderer.shaderbundle。
著色器捆綁包格式本身與您使用的 Flutter 特定版本綁定,並且可能會隨著時間推移而改變。如果您正在撰寫一個建置著色器捆綁包的套件,請不要將生成的 .shaderbundle 檔案檢查到您的原始碼樹中。相反,請使用建置掛鉤來自動化建置流程(如前所述)。
這樣一來,使用您函式庫的開發人員將始終使用正確格式建置新的著色器捆綁包!
現在,您已經自動化了著色器捆綁包的建置,請像常規資產一樣匯入它。將資產條目添加到專案的 pubspec.yaml 中:
1 2 3 flutter: assets: - build/shaderbundles/
在未來,原生資產功能將允許建置掛鉤將資料資產附加到捆綁包中。一旦發生這種情況,就不需要再在建置掛鉤旁邊新增資 * * * * *產匯入規則了。
接下來,新增一些程式碼,在執行時載入著色器。建立 lib/shaders.dart 並新增以下程式碼。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // 複製到:lib/shaders.dart import 'package:flutter_gpu/gpu.dart' as gpu; const String _kShaderBundlePath = 'build/shaderbundles/my_renderer.shaderbundle'; // 注意:如果您正在建立函式庫,則路徑必須以套件名稱為前綴 // 例如: // 'packages/my_cool_renderer/build/shaderbundles/my_renderer.shaderbundle' gpu.ShaderLibrary? _shaderLibrary; gpu.ShaderLibrary get shaderLibrary { if (_shaderLibrary != null) { return _shaderLibrary!; } _shaderLibrary = gpu.ShaderLibrary.fromAsset(_kShaderBundlePath); if (_shaderLibrary != null) { return _shaderLibrary!; } throw Exception("Failed to load shader bundle! ($_kShaderBundlePath)"); }
此程式碼為 Flutter GPU 著色器執行時函式庫建立一個單例 getter。第一次訪問 shaderLibrary 時,會使用 gpu.ShaderLibrary.fromAsset(shader_bundle_path) 使用建置的資產捆綁包初始化執行時著色器函式庫。
專案現在已經設定好使用 Flutter GPU 著色器。是時候渲染那個三角形了!
绘制您的第一個三角形 對於本指南,您將建立一個 RGBA Flutter GPU 紋理和一個 RenderPass,將紋理作為顏色輸出附加到它。然後,您將使用 Canvas.drawImage 在 Widget 中渲染紋理。
為了簡潔起見,您將放棄最佳實務,只會為每一幀重新建置所有資源。
只要您在分配紋理時將其標記為「著色器可讀取」,您就可以將其轉換為 dart:ui.Image。若要將渲染結果顯示在 Widget 樹中,請將其繪製到 dart:ui.Canvas 上!
您可以透過使用自訂畫家為 Widget 樹架設腳手架來存取 Canvas。將 lib/main.dart 的內容替換為以下內容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import 'dart:typed_data'; import 'package:flutter/material.dart'; import 'package:flutter_gpu/gpu.dart' as gpu; // 注意:我們之前在設定著色器捆綁包匯入時建立了它! import 'shaders.dart'; void main() { runApp(const MyApp()); } class MyApp extends StatelessWidget { const MyApp({super.key}); @override Widget build(BuildContext context) { return MaterialApp( title: 'Flutter GPU Triangle Example', home: CustomPaint( painter: TrianglePainter(), ), ); } } class TrianglePainter extends CustomPainter { @override void paint(Canvas canvas, Size size) { // 嘗試存取 `gpu.gpuContext`。 // 如果 Flutter GPU 不受支援,將會拋出異常。 print('Default color format: ' + gpu.gpuContext.defaultColorFormat.toString()); } @override bool shouldRepaint(covariant CustomPainter oldDelegate) => true; }
現在,執行應用程式。提醒一下,Flutter GPU 目前需要 啟用 Impeller 。因此,您必須使用 Impeller 支援的平台。對於本指南,我將以 macOS 為目標。
1 flutter run -d macos --enable-impeller
如果 Flutter GPU 正常工作,那麼您應該會看到預設顏色格式被列印到主控台中。
1 flutter: Default color format: PixelFormat.b8g8r8a8UNormInt
如果 Impeller 未啟用,則在嘗試存取 gpu.gpuContext 時會拋出異常。
1 2 3 4 Exception: Flutter GPU requires the Impeller rendering backend to be enabled. The relevant error-causing widget was: CustomPaint
為了簡便起見,您只會從這裡開始修改 paint 方法。
首先,建立一個 Flutter GPU 紋理,清除它,然後透過將其繪製到 Canvas 上來顯示它。
建立一個與 Canvas 大小相同的紋理。必須選擇一個 StorageMode。在本例中,您將紋理標記為 devicePrivate,因為您將只使用從設備 (GPU) 存取紋理記憶體的指令。
1 2 final texture = gpu.gpuContext.createTexture(gpu.StorageMode.devicePrivate, size.width.toInt(), size.height.toInt())!;
如果透過從主機 (CPU) 上傳資料來覆蓋紋理的資料,則使用 StorageMode.hostVisible。
第三個可用的選項是 StorageMode.deviceTransient,它對於不需要超過單個 RenderPass 壽命的附件很有用(因此它們可以只存在於瓦片記憶體中,並且不需要由 VRAM 分配支援)。通常,深度/模板紋理符合此標準。
接下來,定義一個 RenderTarget。渲染目標包含一組「附件」,描述每個片段的記憶體佈局及其在 RenderPass 開始和結束時的設定/拆卸行為。
本質上,RenderTarget 是 RenderPass 的可重複使用描述器。
現在,定義一個非常簡單的 RenderTarget,它只包含一個顏色附件。
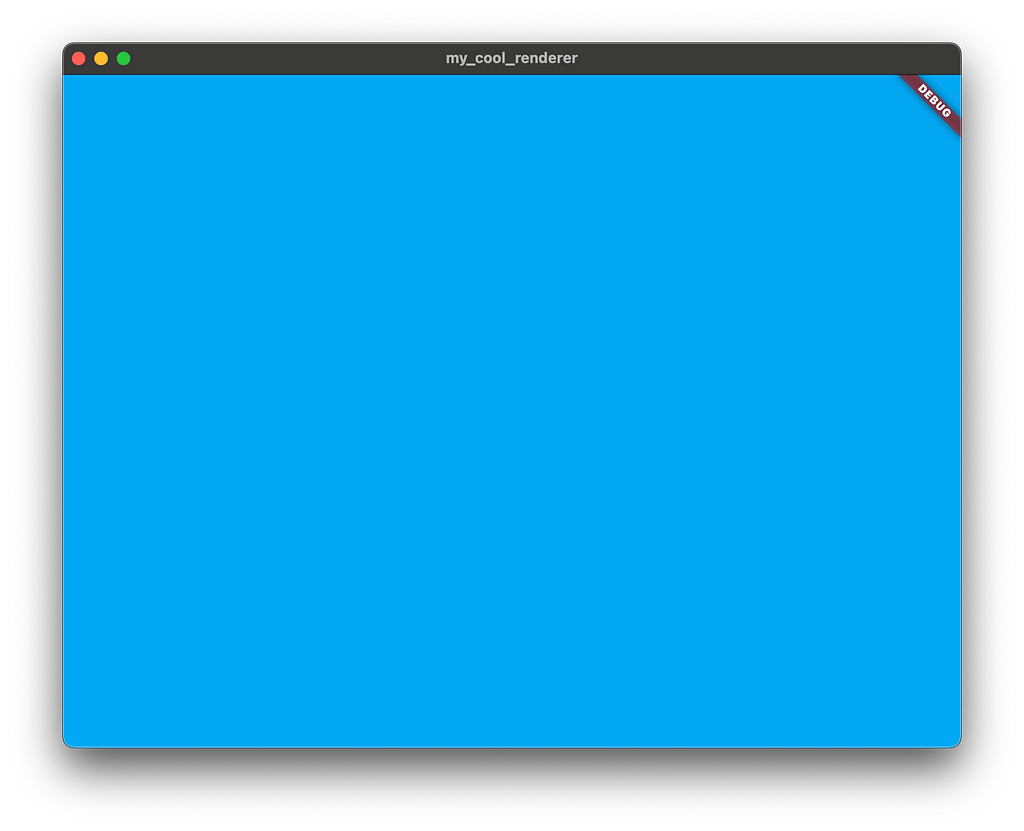
1 2 final renderTarget = gpu.RenderTarget.singleColor( gpu.ColorAttachment(texture: texture, clearValue: Colors.lightBlue));
請注意,此程式碼將 clearValue 設定為淡藍色。每個附件都具有 LoadAction 和 StoreAction,它們分別確定在傳遞的開始和結束時應該對附件的臨時瓦片記憶體執行什麼操作。
預設情況下,顏色附件被設定為 LoadAction.clear(它將瓦片記憶體初始化為給定的顏色)和 StoreAction.store(它將結果儲存到附加的紋理的 VRAM 分配中)。
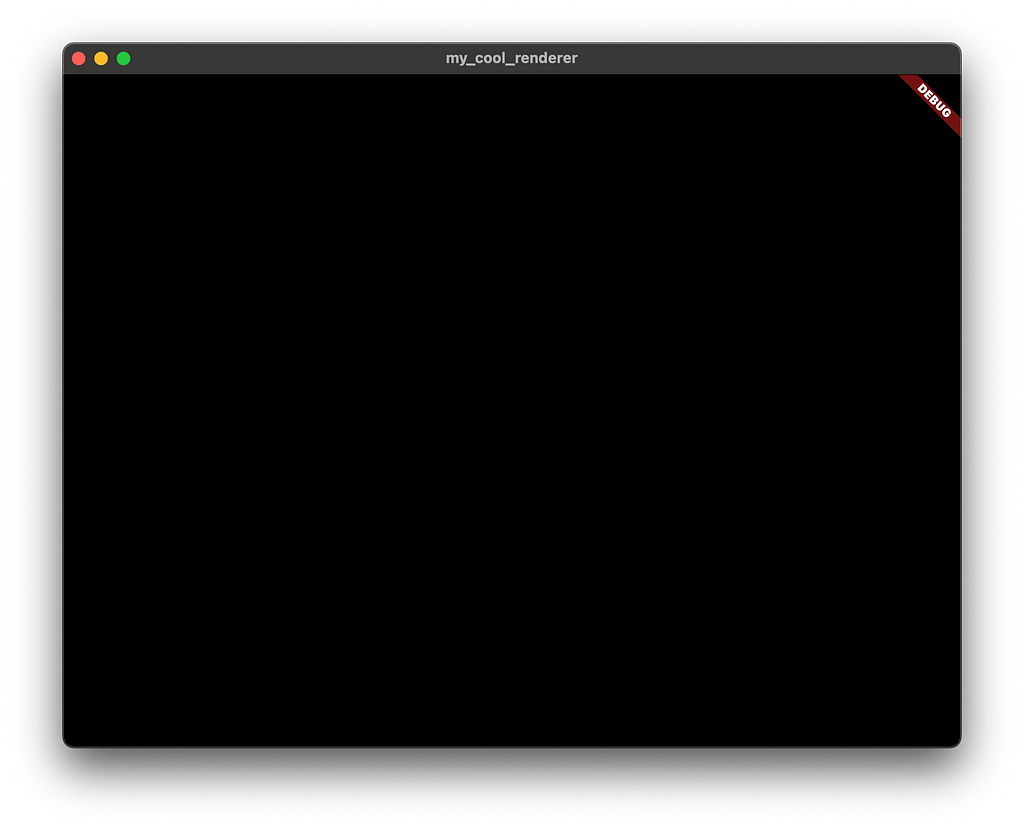
現在,建立一個 CommandBuffer,使用前面的 RenderTarget 從其中產生一個 RenderPass,然後立即提交 CommandBuffer 以清除紋理。
1 2 3 4 final commandBuffer = gpu.gpuContext.createCommandBuffer(); final renderPass = commandBuffer.createRenderPass(renderTarget); // ... 繪製調用將放在這裡! commandBuffer.submit();
剩下的就是將初始化的紋理繪製到 Canvas 上!
1 2 final image = texture.asImage(); canvas.drawImage(image, Offset.zero, Paint());
現在您有了連接到螢幕顯示結果的 RenderPass,您就可以開始繪製三角形了。若要執行此操作,請設定以下內容:
從著色器建立的 RenderPipeline,以及
包含幾何形狀的 GPU 可存取緩衝區(三個頂點位置)。
建立 RenderPipeline 很容易。您只需將函式庫中的頂點和片段著色器組合在一起。
1 2 3 final vert = shaderLibrary['SimpleVertex']!; final frag = shaderLibrary['SimpleFragment']!; final pipeline = gpu.gpuContext.createRenderPipeline(vert, frag);
現在是幾何形狀。回想一下,「SimpleVertex」著色器只有一個輸入:in vec2 position。因此,若要繪製三個頂點,您需要三組兩個浮點數。
1 2 3 4 5 6 7 final vertices = Float32List.fromList([ -0.5, -0.5, // 第一個頂點 0.5, -0.5, // 第二個頂點 0.0, 0.5, // 第三個頂點 ]); final verticesDeviceBuffer = gpu.gpuContext .createDeviceBufferWithCopy(ByteData.sublistView(vertices))!;
剩下的就是繫結新的資源,並呼叫 renderPass.draw() 以完成記錄繪製調用。
1 2 3 4 5 6 7 8 9 10 renderPass.bindPipeline(pipeline); final verticesView = gpu.BufferView( verticesDeviceBuffer, offsetInBytes: 0, lengthInBytes: verticesDeviceBuffer.sizeInBytes, ); renderPass.bindVertexBuffer(verticesView, 3); renderPass.draw();
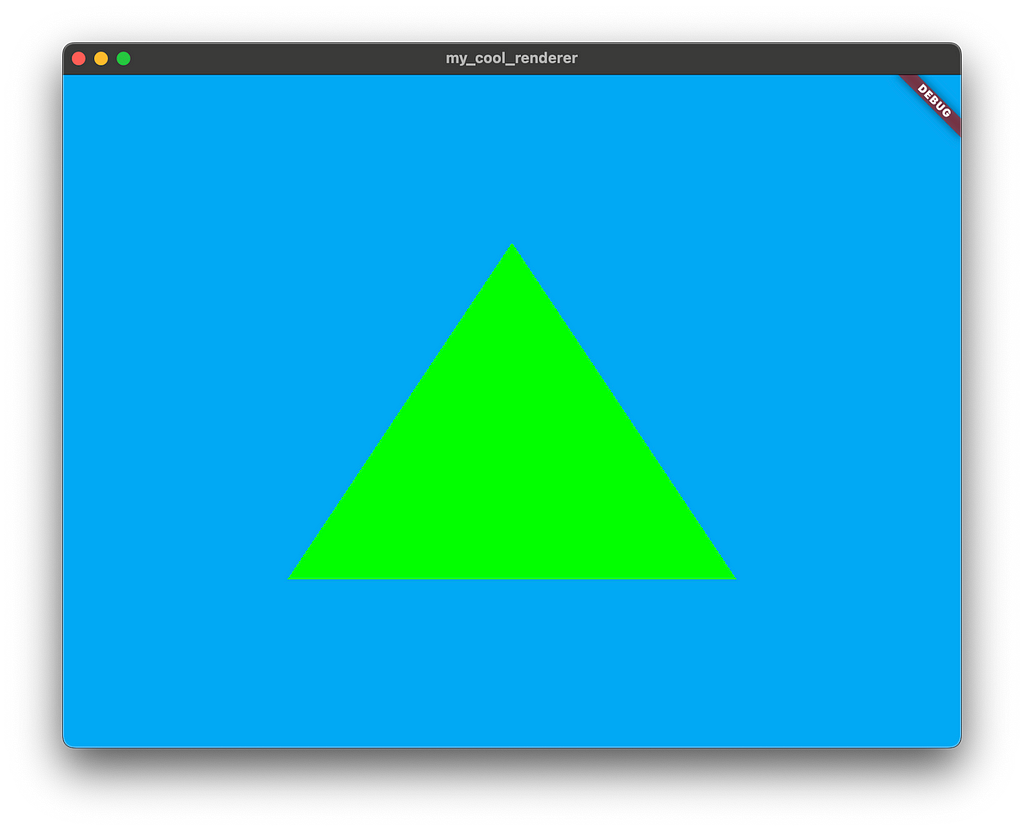
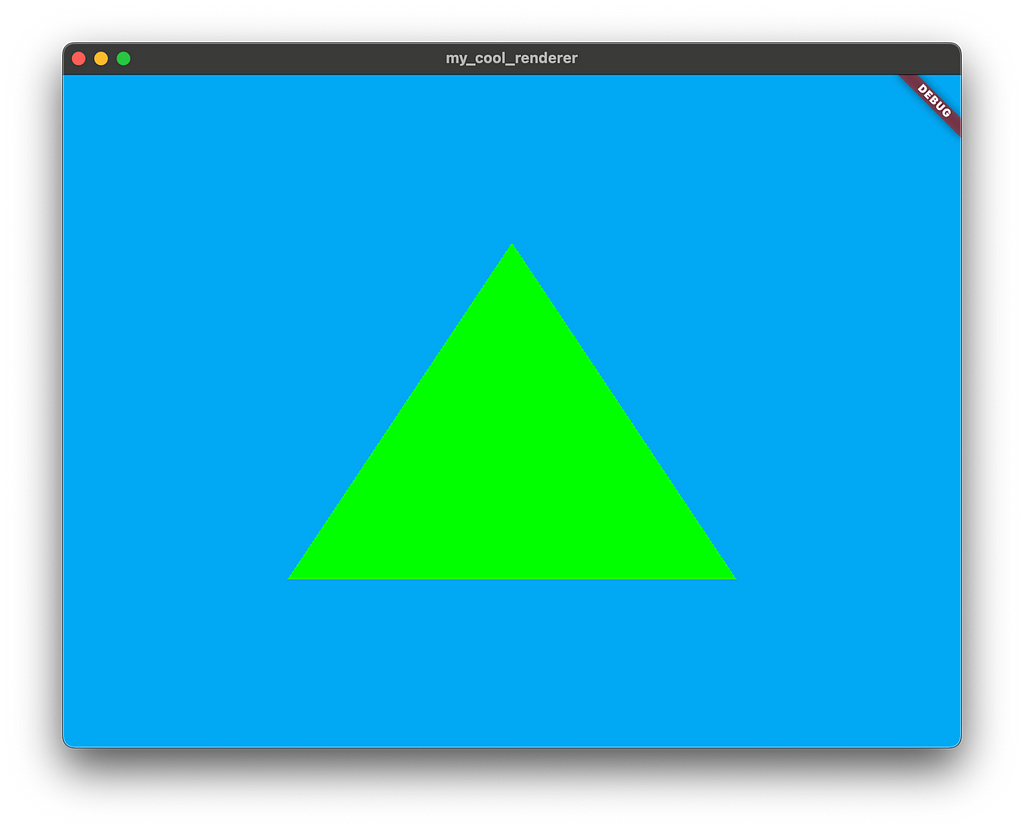
如果您啟動應用程式,您現在應該會看到一個綠色的三角形!
太棒了,您使用 Flutter、Dart 和一點 GLSL 從頭開始建立了一個渲染器!
無論這是否是您第一次渲染三角形,或者您是經驗豐富的圖形專家,我都希望您能繼續使用 Flutter GPU,並查看我們正在開發的套件,例如 Flutter Scene。
在未來,我們希望發佈友好的初學者程式碼實驗室,深入探討 Flutter GPU 的預設行為和最佳實務。我們還沒討論頂點屬性佈局、紋理繫結、統一和對齊要求、管道混合、深度和模板附件、透視校正等等!
在那之前,我建議您探索 Flutter Scene 作為如何使用 Flutter GPU 的更全面的範例。
使用 Flutter Scene 進行 3D 渲染 Flutter Scene(套件 flutter_scene)是一個新的 3D 場景圖套件,由 Flutter GPU 支援,它使 Flutter 開發人員能夠匯入動畫 glTF 模型並渲染即時 3D 場景。
目的是提供一個套件,讓在 Flutter 中輕鬆建立互動式 3D 應用程式和遊戲。
該套件最初是作為一個 dart:ui 擴展,用於用 C++ 編寫的 3D 渲染器,並直接建置到 Flutter 的原生執行時中,但它已經使用更靈活的介面針對 Flutter GPU 重新撰寫。
與 Flutter GPU API 本身一樣,Flutter Scene 目前處於早期預覽狀態,需要 啟用 Impeller 。Flutter Scene 通常與 Flutter GPU API 的重大變更保持同步,因此強烈建議您在試驗 Flutter Scene 時使用 主頻道 。
接下來,使用 Flutter Scene 建立一個應用程式!
設定 Flutter Scene 專案 由於強烈建議您針對 主頻道 使用 Flutter Scene,請從切換到主頻道開始。
1 2 flutter channel main flutter upgrade
接下來,建立一個新的 Flutter 專案。
1 2 flutter create my_3d_app cd my_3d_app
Flutter Scene 依靠實驗性的「原生資產」功能來自動化著色器的建置。您將在稍後使用原生資產來設定自動匯入 Flutter Scene 的 3D 模型。
使用以下命令啟用原生資產。
1 flutter config --enable-native-assets
最後,將 Flutter Scene 添加為專案相依性。
您還需要在與 Flutter Scene 的 API 互動時使用一些 vector_math 構造,因此也添加 vector_math 套件。
1 flutter pub add flutter_scene vector_math
接下來,匯入一個 3D 模型!
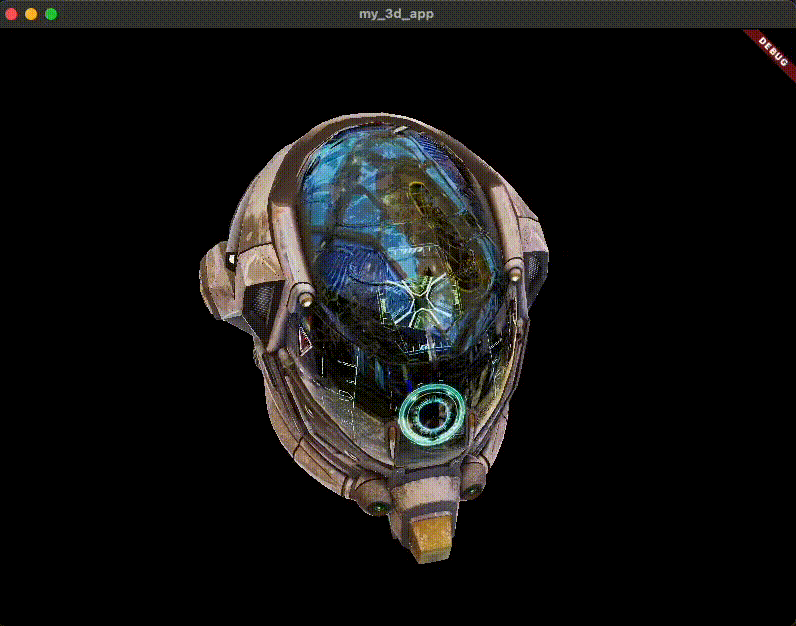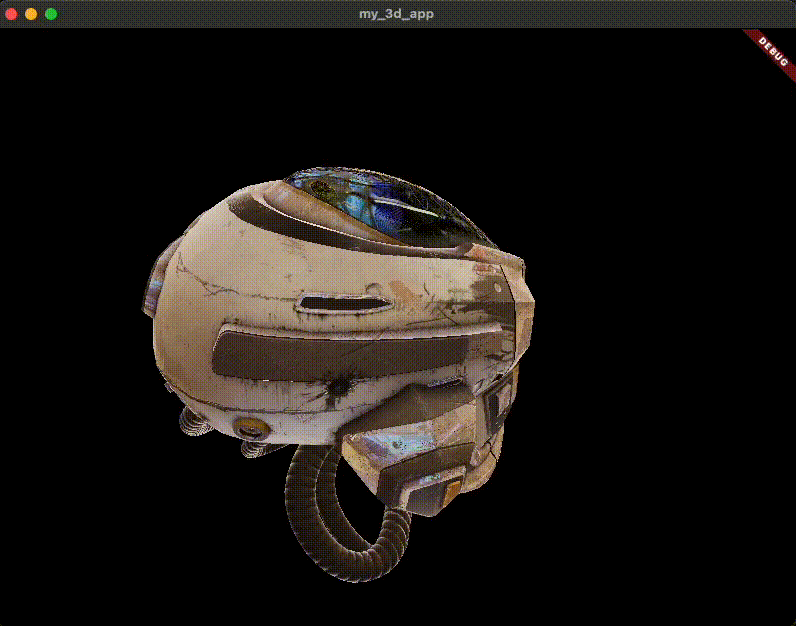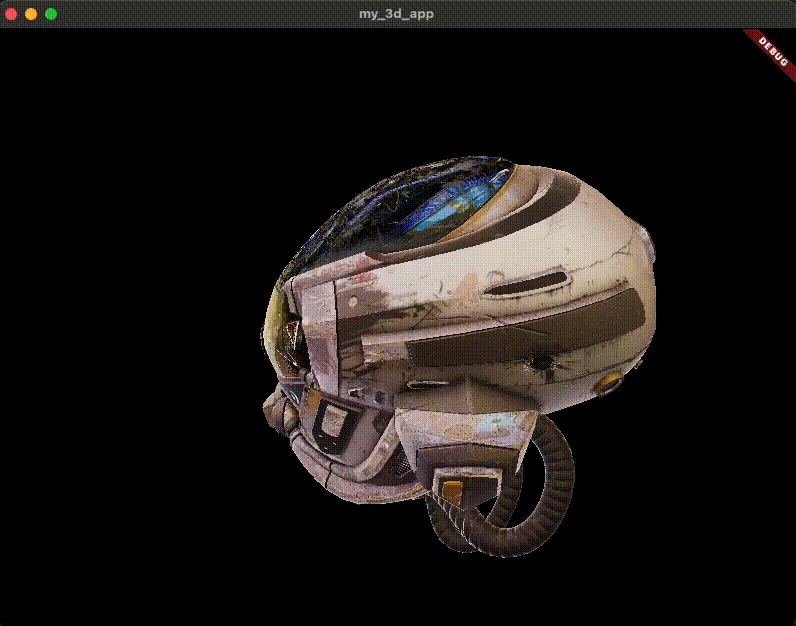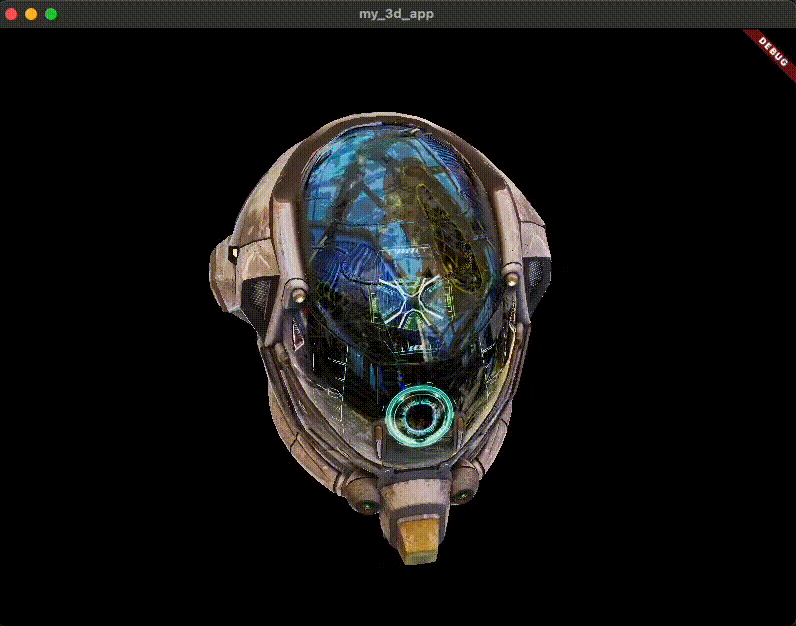
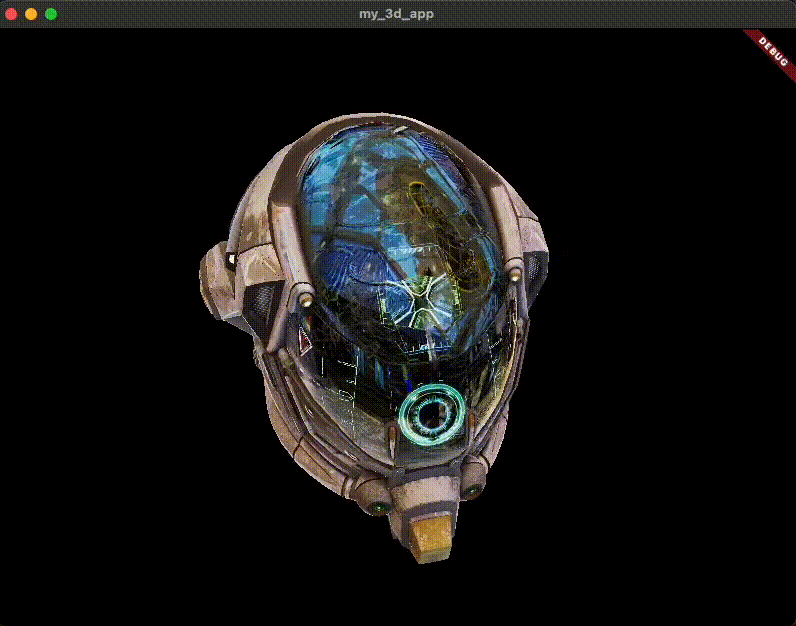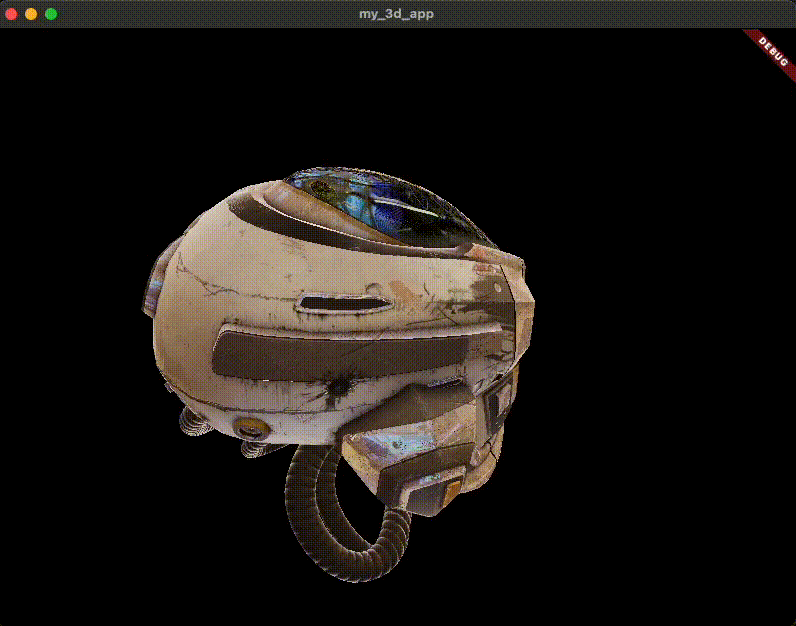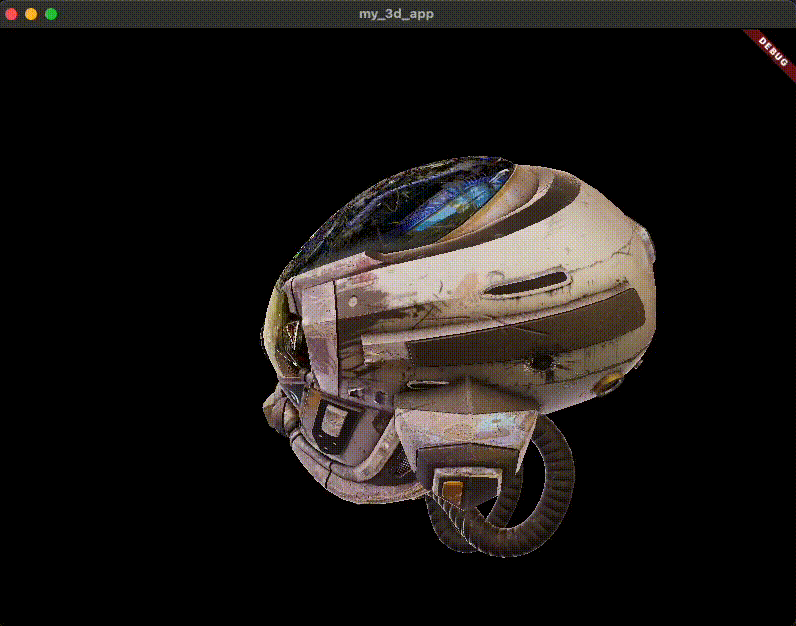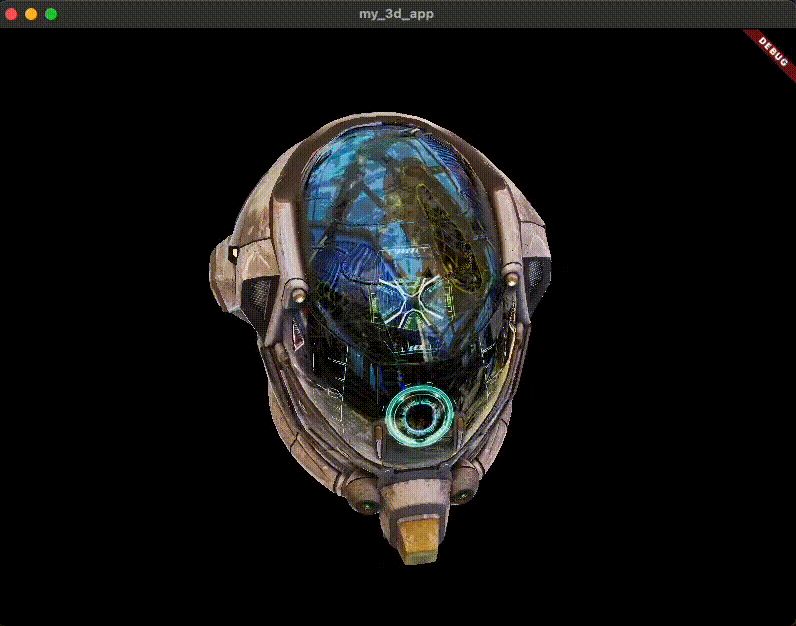
匯入 3D 模型 首先,您需要一個要渲染的 3D 模型。對於本指南,您將使用常見的 glTF 樣本資產: DamagedHelmet.glb 。以下是它的樣子。
原始的 Damaged Helmet 模型由 theblueturtle_ 在 2016 年建立(授權: [CC BY-NC 4.0 國際](https://creativecommons.org/licenses/by-nc/4.0/legalcode))。轉換後的 glTF 版本由 ctxwing 在 2018 年建立(授權: [CC BY 4.0 國際](https://creativecommons.org/licenses/by/4.0/legalcode))。
您可以從 GitHub 上託管的 glTF 樣本資產儲存庫 中獲取它。將 DamagedHelmet.glb 放置在您的專案根目錄中。
1 curl -O https://raw.githubusercontent.com/KhronosGroup/glTF-Sample-Models/main/2.0/DamagedHelmet/glTF-Binary/DamagedHelmet.glb
像大多數即時 3D 渲染器一樣,Flutter Scene 在內部使用專用的 3D 模型格式。您可以使用 Flutter Scene 的離線匯入器工具將標準 glTF 二進制檔案(.glb 檔案)轉換為此格式。
將 flutter_scene_importer 套件作為常規相依性添加到專案中。
1 flutter pub add flutter_scene_importer
添加此套件可以使用 dart run 手動呼叫匯入器。
1 2 3 4 dart --enable-experiment=native-assets \ run flutter_scene_importer:import \ --input "path/to/my/source_model.glb" \ --output "path/to/my/imported_model.model"
您可以透過使用原生資產建置掛鉤來自動執行匯入器。若要執行此操作,請先將 native_assets_cli 作為常規專案相依性安裝。
1 flutter pub add native_assets_cli
現在您可以撰寫建置掛鉤了。使用以下內容建立 hook/build.dart。
1 2 3 4 5 6 7 8 9 10 import 'package:native_assets_cli/native_assets_cli.dart'; import 'package:flutter_scene_importer/build_hooks.dart'; void main(List<String> args) { build(args, (config, output) async { buildModels(buildConfig: config, inputFilePaths: [ 'DamagedHelmet.glb', ]); }); }
使用 flutter_scene_importer 中的 buildModels 公用程式,提供要建置的模型列表。路徑相對於專案的建置根目錄。
當 Flutter 工具建置專案時,buildModels 現在將建置著色器捆綁包,並將結果輸出到套件根目錄下的 build/models/DamagedModel.model。
匯入的模型格式本身與您使用的 Flutter Scene 特定版本綁定,並且會隨著時間推移而改變。在撰寫使用 Flutter Scene 的應用程式或函式庫時,請勿將生成的 .model 檔案檢查到您的原始碼樹中。相反,請使用建置掛鉤從您的原始模型中生成它們(如前所述)。
這樣一來,隨著時間推移升級 Flutter Scene 時,您將始終使用正確格式建置新的 .model 檔案!
接下來,像常規資產一樣匯入模型。將資產條目添加到專案的 pubspec.yaml 中。
1 2 3 flutter: assets: - build/models/
在未來,原生資產功能將允許建置掛鉤將資料資產附加到捆綁包中。一旦發生這種情況,就不需要再在建置掛鉤旁邊新增資產匯入規則了。
渲染 3D 場景 現在是應用程式的程式碼了。
首先,建立一個有狀態的 Widget,用於在多個幀中保留 Scene。
您將根據時間進行動畫處理,因此將 SingleTickerProviderStateMixin 添加到狀態,以及一個 elapsedSeconds 成員。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import 'dart:math'; import 'package:flutter/material.dart'; import 'package:flutter/scheduler.dart'; import 'package:flutter_scene/camera.dart'; import 'package:flutter_scene/node.dart'; import 'package:flutter_scene/scene.dart'; import 'package:vector_math/vector_math.dart'; void main() { runApp(const MyApp()); } class MyApp extends StatefulWidget{ const MyApp({super.key}); @override MyAppState createState() => MyAppState(); } class MyAppState extends State<MyApp> with SingleTickerProviderStateMixin { double elapsedSeconds = 0; Scene scene = Scene(); @override Widget build(BuildContext context) { return MaterialApp( title: 'My 3D app', home: Placeholder(), ); } }
執行應用程式作為冒煙測試,以確保沒有錯誤。請記住要 啟用 Impeller !
1 flutter run -d macos --enable-impeller
在繼續之前,請為動畫設定計時器。覆蓋 MyAppState 中的 initState 以呼叫 createTicker。
1 2 3 4 5 6 7 8 9 10 @override void initState() { createTicker((elapsed) { setState(() { elapsedSeconds = elapsed.inMilliseconds.toDouble() / 1000; }); }).start(); super.initState(); }
只要 Widget 可見,計時器回呼就會為每一幀被呼叫。呼叫 setState 會觸發此 Widget 在每一幀重建。
接下來,載入之前放置在專案中的 3D 模型,並將其添加到 Scene 中。
使用 Node.fromAsset 從資產捆綁包中載入模型。將以下程式碼放置在 initState 中。
1 2 3 4 Node.fromAsset('build/models/DamagedHelmet.model').then((model) { model.name = 'Helmet'; scene.add(model); });
Node.fromAsset 會異步地從資產捆綁包中反序列化模型,並在模型準備好添加到場景中時解析返回的 Future。
現在,MyAppState.initState 應該如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @override void initState() { createTicker((elapsed) { setState(() { elapsedSeconds = elapsed.inMilliseconds.toDouble() / 1000; }); }).start(); Node.fromAsset('build/models/DamagedHelmet.model').then((model) { model.name = 'Helmet'; scene.add(model); }); super.initState(); }
但是,您仍然沒有實際渲染 3D Scene!若要執行此操作,請使用 Scene.render,它需要 UI Canvas、Flutter Scene Camera 和一個大小。
存取 Canvas 的一種方法是建立一個 CustomPainter:
1 2 3 4 5 6 7 8 9 10 11 12 13 class ScenePainter extends CustomPainter { ScenePainter({required this.scene, required this.camera}); Scene scene; Camera camera; @override void paint(Canvas canvas, Size size) { scene.render(camera, canvas, viewport: Offset.zero & size); } @override bool shouldRepaint(covariant CustomPainter oldDelegate) => true; }
不要忘記將 shouldRepaint 覆蓋設置為返回 true,以便在每次重建發生時自訂畫家都會重新繪畫。
最後,將 CustomPainter 添加到源樹中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @override Widget build(BuildContext context) { final painter = ScenePainter( scene: scene, camera: PerspectiveCamera( position: Vector3(sin(elapsedSeconds) * 3, 2, cos(elapsedSeconds) * 3), target: Vector3(0, 0, 0), ), ); return MaterialApp( title: 'My 3D app', home: CustomPaint(painter: painter), ); }
此程式碼指示相機沿著一個連續的圓圈移動,但始終面向原點。
最後,啟動應用程式!
1 flutter run -d macos --enable-impeller
以下是我們組合的完整源程式碼。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import 'dart:math'; import 'package:flutter/material.dart'; import 'package:flutter_scene/camera.dart'; import 'package:flutter_scene/node.dart'; import 'package:flutter_scene/scene.dart'; import 'package:vector_math/vector_math.dart'; void main() { runApp(const MyApp()); } class MyApp extends StatefulWidget { const MyApp({super.key}); @override MyAppState createState() => MyAppState(); } class MyAppState extends State<MyApp> with SingleTickerProviderStateMixin { double elapsedSeconds = 0; Scene scene = Scene(); @override void initState() { createTicker((elapsed) { setState(() { elapsedSeconds = elapsed.inMilliseconds.toDouble() / 1000; }); }).start(); Node.fromAsset('build/models/DamagedHelmet.model').then((model) { model.name = 'Helmet'; scene.add(model); }); super.initState(); } @override Widget build(BuildContext context) { final painter = ScenePainter( scene: scene, camera: PerspectiveCamera( position: Vector3(sin(elapsedSeconds) * 3, 2, cos(elapsedSeconds) * 3), target: Vector3(0, 0, 0), ), ); return MaterialApp( title: 'My 3D app', home: CustomPaint(painter: painter), ); } } class ScenePainter extends CustomPainter { ScenePainter({required this.scene, required this.camera}); Scene scene; Camera camera; @override void paint(Canvas canvas, Size size) { scene.render(camera, canvas, viewport: Offset.zero & size); } @override bool shouldRepaint(covariant CustomPainter oldDelegate) => true; }
Flutter 光明的未來 如果您能夠成功地遵循這些指南中的其中一個並讓它運行起來:太棒了,恭喜!
Flutter GPU 和 Flutter Scene 都非常年輕,平台支援有限。但我想總有一天,我們會懷念這些不起眼的開端。
隨著 Impeller 的推廣,Flutter 團隊完全掌控了渲染堆疊,因為我们需要針對 Flutter 的用例專門化渲染器。現在,我們正在開啟 Flutter 歷史上的一個新篇章。一個由您共同掌控渲染的篇章!
Flutter Scene 最初是 Impeller 中的 C++ 組件,與 2D Canvas 渲染器一起,帶有一個精簡的 dart:ui 擴展。在我構建它時,我已經意識到 Flutter Engine 不會是它的最終目的地。
3D 渲染器的架構決策海洋是廣闊